3. 사용 방법
3-3. 파이프라인 생성
DEEP:PHI 플랫폼의 핵심은 Flow space에서 좌측의 모듈들을 편리하게 드래그&드롭으로 사용하는 것입니다. 생성된 모듈들은 연결 방향 기준 좌측에서 우측으로 데이터가 자동으로 이동하며 모듈별로 연산을 수행합니다. 각 모듈의 입/출력 결과도 플랫폼 상에서 바로 확인 가능하기 때문에 빠르고 편리하게 연구를 수행할 수 있습니다.
의료 영상을 활용한 인공지능 연구 단계는 크게 4단계로 구분되며 데이터셋 업로드 - 데이터셋 가공 - 신경망 학습 - 결과 분석 등으로 구성되어 있습니다. DEEP:PHI 플랫폼에선 각 단계별로 다양한 수행기능들을 모듈화하여 별도의 코딩작업 없이 손쉽게 사용자들이 사용할 수 있습니다.
DEEP:PHI 플랫폼의 모듈 구성은 Dataset, Image Processing, Neural Network, Data Manipulation으로 구분되어 있습니다.
Dataset 모듈은 사용자가 데이터셋을 업로드해서 사용하는 사용자 데이터셋 모듈과 딥노이드에서 공유하고 있는 Shared 데이터셋 모듈로 구분되어 있습니다. 데이터셋을 업로드하면 업로드 과정에서 입력한 정보대로 데이터셋의 촬영 부위로 구분되어 Dataset 카테고리 상에서 해당 카테고리로 찾아가거나 검색창에서 업로드한 데이터셋의 이름을 검색하여 좌측 메뉴에서 중앙의 Flow space로 드래그&드롭하여 사용합니다.
1) Dataset 모듈로 데이터셋 불러오기
- 업로드된 데이터셋은 촬영 부위별로 구분되어 있습니다.
- Shared Dataset은 별도의 표시가 되어있지 않으며 사용자가 직접 업로드한 데이터셋은 데이터셋 모듈 이름 좌측에 My 태그가 표시되어 있습니다.
- +Create 버튼을 눌러 데이터셋 업로드를 수행할 수 있습니다.
- 사용하고자 하는 데이터셋을 클릭해서 Flow space로 가져간 다음(드래그) 클릭 해제(드랍)하면 Flow space에 데이터셋이 생성됩니다.
- 중앙 하단은 데이터셋을 확인하고 모듈의 실행 로그를 확인하는 공간입니다.
- 우측 영역은 해당 모듈의 정보와 데이터 시각화, 속성값 등을 확인하는 공간입니다.
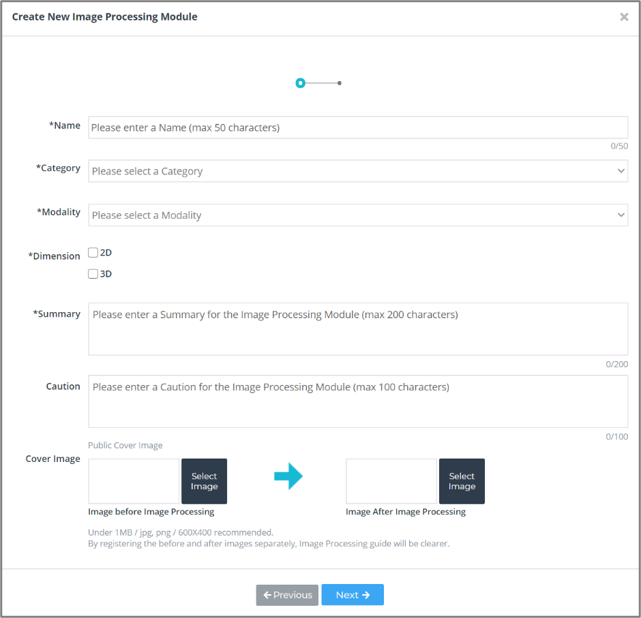
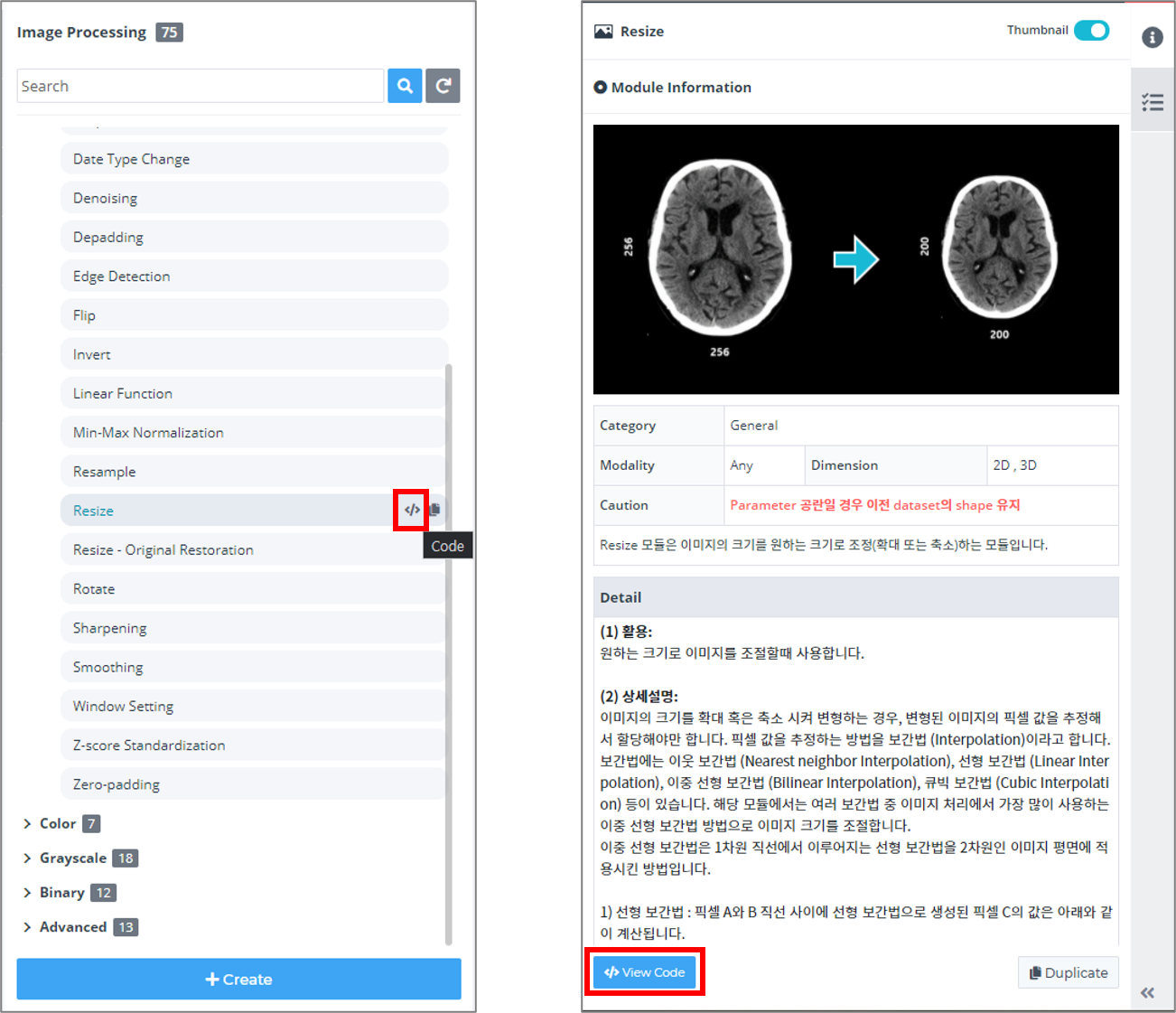
2) Image Processing 모듈 사용하기
Image Processing은 일반적으로 영상처리를 의미합니다.
DEEP:PHI 플랫폼에선 다양한 영상처리 알고리즘을 활용하여 의료 영상 데이터를 가공할 수 있습니다.
인공지능 알고리즘의 핵심이 되는 신경망은 입력 데이터의 형태에 따라 학습 성능이 유의미한 차이를 보입니다.
따라서 단순히 Raw 데이터를 그대로 신경망에 입력하는 것이 아니라 각 데이터셋에 맞게, 사용자가 원하는 연구목적에 맞게 데이터를 가공해서 신경망에 입력하는 것이 성능을 높일 수 있는 좋은 방법입니다.
데이터셋 모듈과 마찬가지로 Image Processing 모듈 역시 좌측 메뉴에서 드래그&드롭으로 간편하게 Flow space에서 모듈 간 연결을 통해 사용할 수 있습니다.
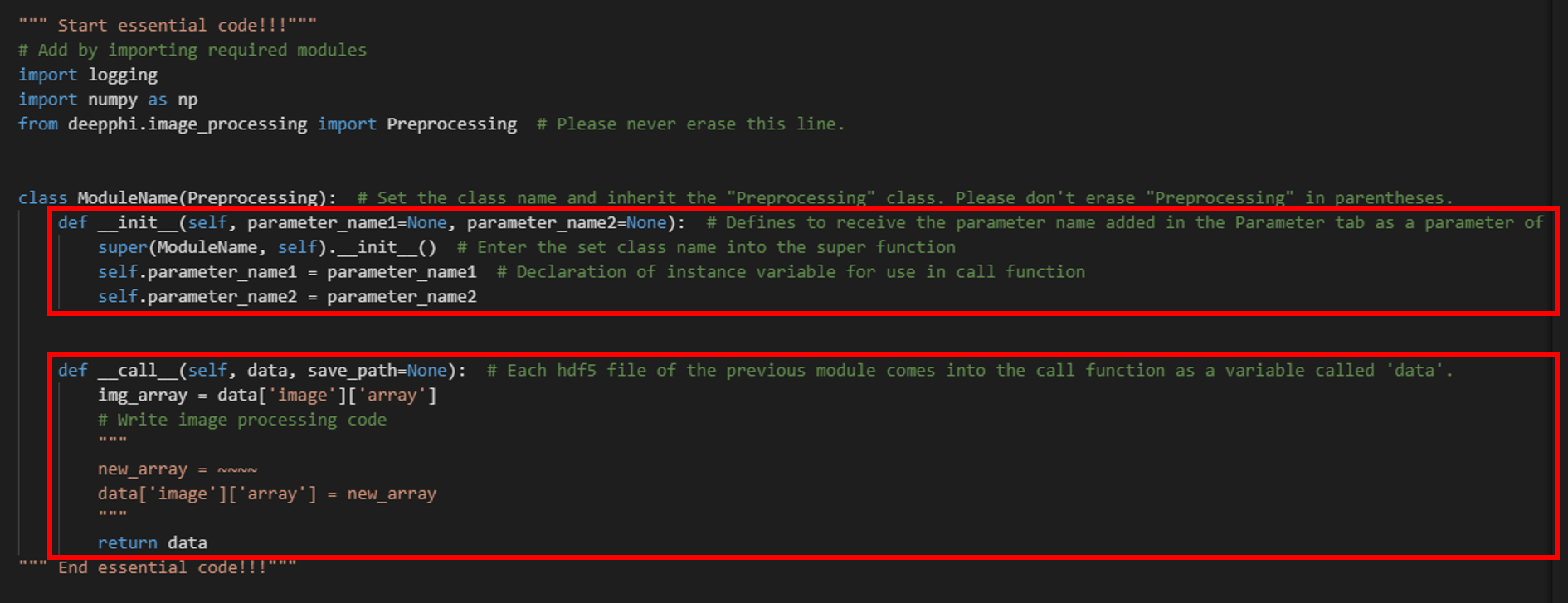
또한 Custom 기능이 필요한 경우를 대비해 사용자가 직접 코드 작업이 가능한 파이썬 코드 에디터를 별도로 제공하고 있습니다.
① 데이터셋 모듈의 오른쪽 영역에 사용할 영상처리 모듈을 드래그&드롭하여 배치합니다.
② 배치한 모듈을 모듈 아이콘의 가운데에 커서를 두면 연결 모드가 활성화됩니다(클립모양 표시).
클립 아이콘을 클릭한 상태에서 드래그하고 다음 모듈로 연결하면 위 사진과 같이 녹색 선이 연결되고, 클릭 해제를 하면 모듈들이 화살표로 연결됩니다.
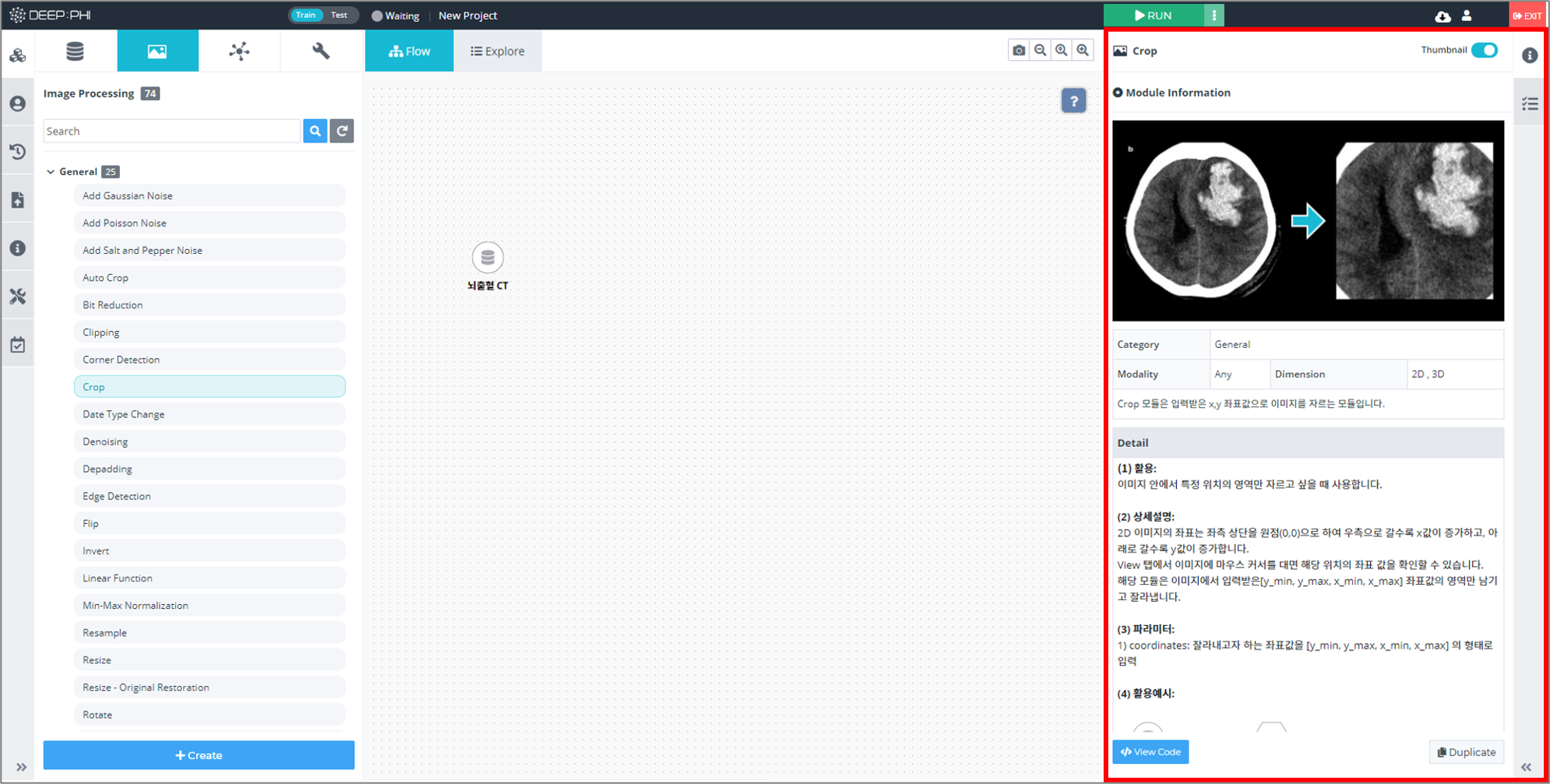
③ 각 Image Processing 모듈은 모듈의 기능과 상세 설명, 활용 예시가 우측 Information 탭에 입력되어 있습니다.
해당 Information을 읽어보고 상황에 맞는 모듈을 사용하면 됩니다.
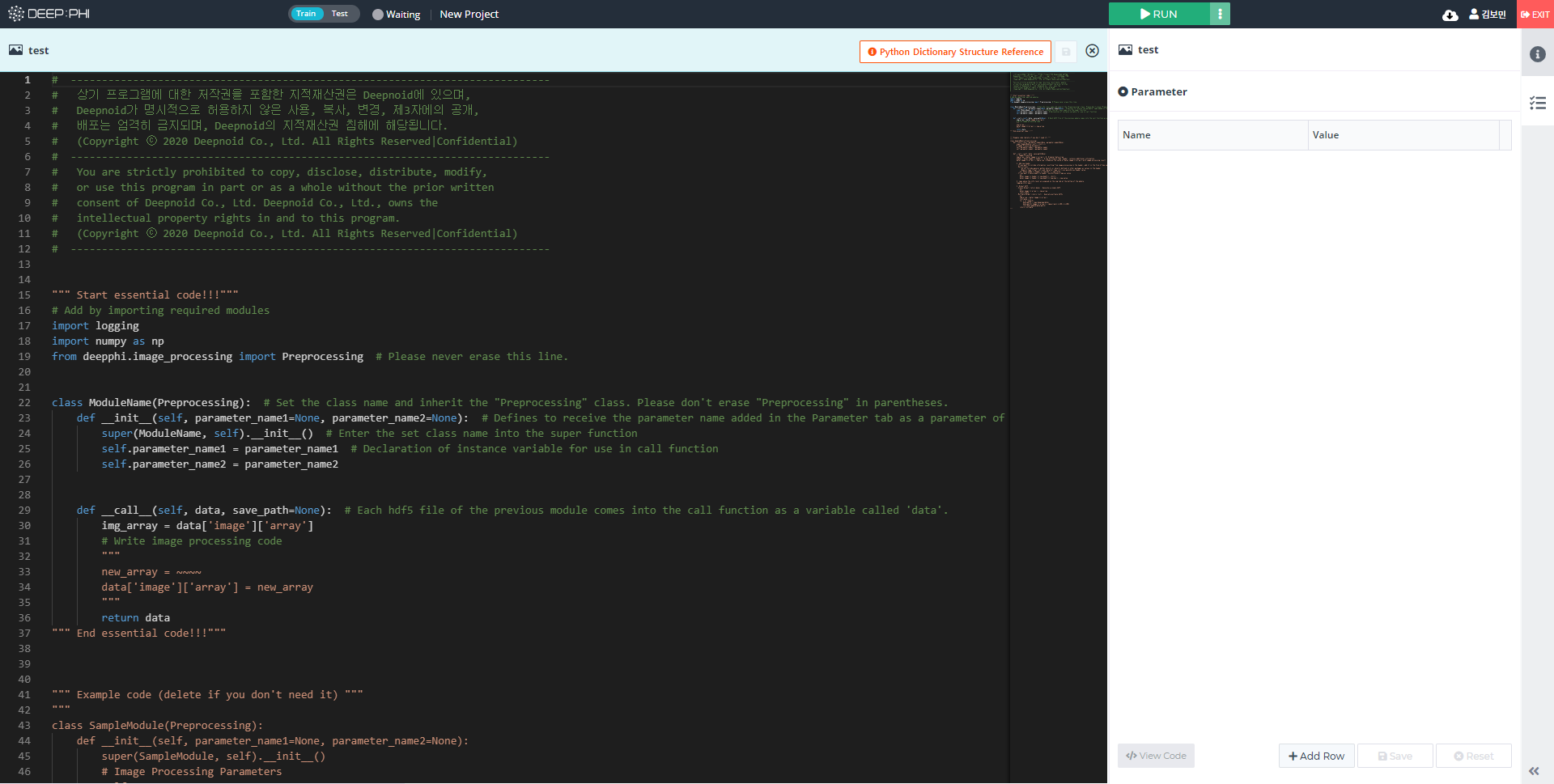
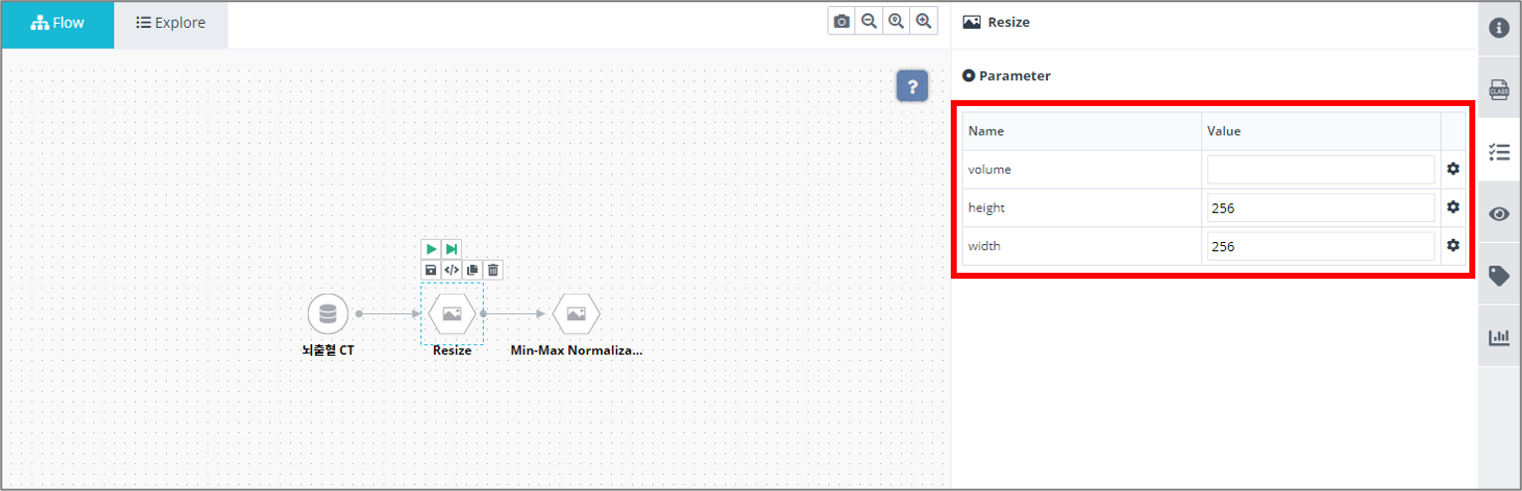
④ Information 탭 아래에는 해당 모듈의 설정값을 변경할 수 있습니다.
⑤ Attribute 탭에선 선택한 데이터에 대한 다양한 속성값을 확인할 수 있습니다.
⑥ 데이터셋 모듈과 Image Processing 모듈을 연결하고 실행시키면 각 모듈 별 Output 결과를 오른쪽 Processing Result 탭에서 확인할 수 있습니다.
위 예시처럼 영상이 각 모듈을 거치면서 어떻게 변화하는지 직접 눈으로 확인할 수 있으며 이러한 과정을 통해 어떤 모듈을 사용해 데이터셋을 가공할지 연구할 수 있습니다.
3) Neural Network 모듈 사용하기
마지막 단계로 이제 가공한 데이터셋을 신경망에 입력하여 학습과정을 수행합니다.
DEEP:PHI 플랫폼의 인공지능 알고리즘들은 지도학습(Supervised Learning) 기반의 인공지능 알고리즘들이 탑재되어 있습니다.
신경망(Neural Network)은 생물의 신경계를 수학적으로 모사하여 작동하도록 설계된 알고리즘입니다.
다양한 방법을 사용해서 입력 데이터로부터 의미있는 특징(Feature)들을 추출하고 이 특징들을 각 신경망 노드들이 학습하면서 정답을 찾아가도록 만들어져 있습니다.
크게 사용자가 신경망을 통해 데이터를 분석하려는 목적에 따라 Classification, Segmentation, Object Detection으로 신경망의 역할을 나눌 수 있습니다.
Classification : 입력 데이터를 통해 데이터의 Class를 분류하는 작업을 수행합니다.
ex) 정상 환자 vs 비정상 환자의 구분, 양성 종양 vs 악성 종양의 구분 등Segmentation : 입력 데이터를 통해 데이터의 특정 영역을 분할하는 작업을 수행합니다.
ex) Brain MRI 영상에서 enhancing tumor, tumor core, whole tumor를 구분하여 추출Detection : 입력 데이터를 통해 데이터에서 물체의 위치를 탐지하는 작업을 수행합니다.
ex) Lung CT 영상에서 Lung Nodule의 위치를 좌표로 탐지
DEEP:PHI 플랫폼에선 인공지능 연구원들이 실제 연구 과정에서 사용하고 있는 다양한 종류의 신경망들을 지속적으로 플랫폼에 업데이트하고 있습니다.
각 신경망들은 위 분석 목적에 따라 분류되어 있으며 Dataset 모듈, Image Processing 모듈과 마찬가지로 드래그&드롭을 통해 모듈을 Flow space로 가져오고 모듈끼리 연결하여 사용할 수 있습니다.
또한 신경망 구조를 직접 변경하고자 하는 사용자들을 위해 블럭 장난감을 조립하듯이 신경망의 각 계층을 편리하게 조립할 수 있도록 별도의 코딩 과정이 필요없는 GUI 기반의 신경망 모델 빌더를 제공합니다.
① Neural Network 모듈을 드래그&드롭하여 배치합니다.
② 배치한 모듈을 모듈 아이콘의 가운데에 커서를 두면 연결 모드가 활성화됩니다(클립모양 표시).
클립 아이콘을 클릭한 상태에서 드래그하고 다음 모듈로 연결하면 위 사진과 같이 녹색 선이 연결되고, 클릭 해제를 하면 모듈들이 화살표로 연결됩니다.
③ 각 Neural Network 모듈들도 Image Processing 모듈들처럼 모듈의 기능과 상세 설명, 활용 예시가 우측 Information 탭에 입력되어 있습니다.
해당 Information을 읽어보고 상황에 맞는 모듈을 사용하면 됩니다.
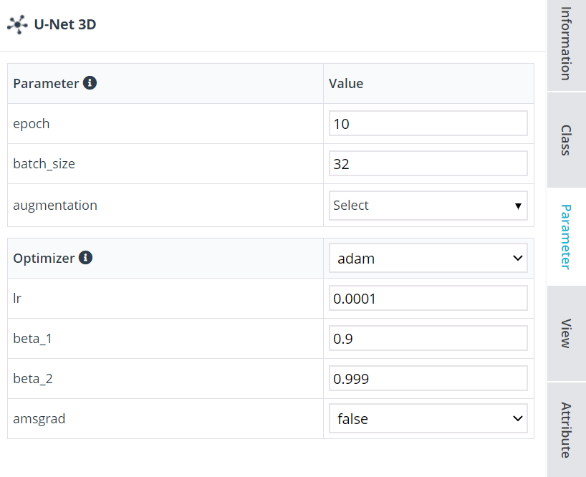
④ Information 탭 아래에 있는 Parameter 탭에서 모듈의 설정값을 변경할 수 있습니다.
4) Project Run 실행하기
이제 프로젝트 파이프라인이 전부 연결되었으므로 파이프라인을 실행시켜 학습을 수행할 수 있습니다.
프로젝트 파이프라인을 실행하는 방법은 두 가지가 있습니다. 전체 파이프라인을 한 번에 실행시키거나, 개별 모듈 단위로 실행시킬 수 있습니다.
I. 전체 실행

프로젝트 전체 실행은 상단 우측의 RUN 버튼을 눌러 한 번에 파이프라인의 좌측부터 우측까지 순차적으로 모듈을 실행할 수 있습니다.
각 실행단계에선 실행 로그와 Output 파일을 이미지 뷰어를 통해 확인 가능합니다.
RUN 버튼의 우측 점선 버튼은 세부적으로 프로젝트 전체 실행을 수행할 수 있는 기능 들을 지원하고 있습니다.
해당 버튼을 클릭하면 아래와 같이 3가지의 실행 아이콘이 팝업 됩니다.

RUN(All modules) 버튼은 기존의 RUN 버튼과 동일한 기능을 수행합니다. 파이프라인의 가장 좌측 모듈부터 순차적으로 연결된 모듈을 전체적으로 실행합니다.
RUN (From first incomplete module) 버튼은 실행되지 않은 모듈 중 가장 좌측의 모듈로부터 순차적으로 연결된 모듈을 실행합니다.
Sample RUN 버튼은 전체 데이터셋을 활용해서 실행하는 것이 아닌 데이터셋의 일부 만을 사용해서 프로젝트 파이프라인을 실행합니다. 데이터셋이 매우 커서 각 모듈의 처리 시간이 매우 긴 경우 한번 모듈을 잘못 사용하면 처음부터 다시 오랜 시간에 걸쳐 모듈 들을 실행해야 합니다. 이러한 것을 방지하기 위해 데이터셋의 일부를 추출해서 Sample RUN으로 먼저 전체 파이프라인을 실행하여 데이터의 변화를 살펴보고 수정 과정을 거친 뒤 최종적으로 프로젝트를 실행을 하는 것이 효율적으로 연구 프로젝트를 수행할 수 있는 방법입니다.
II. 모듈 실행
모듈의 실행은 두 가지 방법이 있습니다.
- 좌측의 Play 버튼을 클릭하면 해당 모듈 하나만 실행이 됩니다.
- 우측의 Step forward 버튼을 클릭하면 해당 모듈과 해당 모듈의 뒤(우측)로 연결되어 있는 모든 모듈들이 순차적으로 실행됩니다.